Scenario-based Learning - A New Learning Perspective. Node.js - Part 1
Scenario-based Learning - A New Learning Perspective. Node.js - Part 1
Welcome to this new Article series. Scenario-based Learning - A New Learning Perspective. Node.js - Part 1
Whenever I want to learn new technology, I can able to find a lot of resources to learn the syntax of a particular programming language/technology.
But, I couldn’t able to find resources which put me a production level problem scenario’s, from which I can able to learn the technology.
so, I thought why don’t I create a one which will be helpful for developers like me to learn a programming language or technology by practicing a problem scenario.
please do share it. Subscribe to my newsletter for further updates .
To Learn Javascript, read this article series https://cloudnweb.dev/category/web-dev/
Why it is Important?
Every time, we learn something. we go and find something to implement it to get a good grasp of it. From, a beginner perspective of the technology. it is great.
But, there is a gap between a beginner who learns the technology to a person who works in the production level application. we really don’t know what kind of a problem the particular technology solves in real industrial applications until we work for a company/ a freelancing project
What I am going to do is, I will be sharing all the problem scenarios that I faced in the production. So, the beginner for the particular technology can replicate the scenario on his own and learn from it.
Basically, he/she is going to gain my experience through learning on his own. So, In the future, if he faces the same problem scenario, he/she can tackle it in an efficient way.
Node.js Experience
This Blog series is from my Node.js Experience. Basically, I am a React,Node.js and MongoDB Developer.
Soon, I will share problem scenarios for React as well. I will start with a simple scenario this week. In upcoming articles, I will share more complex scenarios where you can learn from it.
Scenario based Learning A New Learning Perspective
Problem Scenario
Recently, I faced a situation where I need to read a large sized file from internet and write it in my server.
To do this in Node.js, you can think of it like just read the file and write directly into the server.
But there is a problem with this approach, Let’s say that we implement something like this
const fs = require("fs");
fs.readFileSync("sample.mkv", (err, data) => {
if (err) throw err;
fs.writeFileSync("output", data, (err) => {
if (err) throw err;
});
});the problem is,
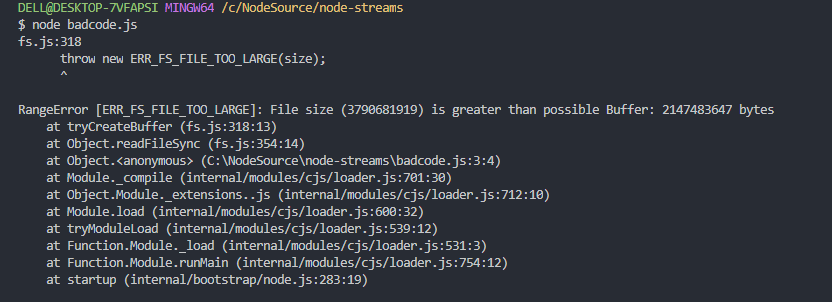
There is a limit in Node.js Buffer, we can’t store more than the Buffer size.
To address this problem, we need something called Stream in Node.js.
What is Stream?
Storing a complete file in Memory is so expensive. also, we need to store the file without having this problem. To solve this, we use Stream which is nothing but processing the data in chunks.
Stream process the huge data in a chunk by chunk which store the chunk in memory one at a time.
Solution
we need to create a readable stream which reads the data from the source and writable stream which writes the data to the destination.
If you are new to Node.js, I would suggest you watch some tutorials and try this problem scenarios.then, it will be easy to understand what is going on.
Solution Code
const fs = require("fs");
const stream = require("stream");
//creating a readable stream
const readable = fs.createReadStream("sample");
//creating a writable stream
const writable = fs.createWriteStream("output");
fs.stat("sample", (err, stats) => {
this.filesize = stats.size;
this.counter = 1;
//this is an event which handles the data in chunks
readable.on("data", (chunk) => {
let percentageCopied =
((chunk.length * this.counter) / this.fileSize) * 100;
process.stdout.clearLine();
process.stdout.cursorTo(0);
process.stdout.write(`${Math.round(percentageCopied)}%`);
//writing the chunk into writable stream output
writable.write(chunk);
this.counter += 1;
});
readable.on("end", (e) => {
console.log("Read is completed");
});
readable.on("error", (e) => {
console.log("Some error occured: ", e);
});
writable.on("finish", () => {
console.log("Successfully created the file copy!");
});
});It reads the data from the local file and writes it again from another local file. For the conceptual purpose, I have used the local file itself rather than a file from the internet.
There is also a problem with this approach, if you analyze the Memory Manager in your machine while this code runs. it will take a lot of memory.
The reason being is, Disk write will not cope up with a speed of Disk Read . Reading a disk will be faster than Writing into a disk.
Beauty is, we can solve this problem too.
Efficient Solution
Node.js Stream has a solution for the above problem which is backpressure
const stream = require("stream");
const fs = require("fs");
let fileName = "sample";
const readabale = fs.createReadStream(fileName);
const writeable = fs.createWriteStream("output");
fs.stat(fileName, (err, stats) => {
this.fileSize = stats.size;
this.counter = 1;
this.fileArray = fileName.split(".");
try {
this.fileoutputName =
"output" + "/" + this.fileArray[0] + "_Copy." + this.fileArray[1];
} catch (e) {
console.exception("File name is invalid");
}
process.stdout.write(`File: ${this.fileoutputName} is being created:`);
readabale.on("data", (chunk) => {
let percentage = ((chunk.length * this.counter) / this.fileSize) * 100;
process.stdout.clearLine(); // clear current text
process.stdout.cursorTo(0);
process.stdout.write(`${Math.round(percentage)}%`);
this.counter += 1;
});
//Note this line : Read Stream pipes the Write Streams
readabale.pipe(writeable);
// In case if we have an interruption while copying
writeable.on("unpipe", (e) => {
process.stdout.write("Write Failed!");
});
});The only change that we did with the previous solution is to pipe the readable stream to the writable stream
it will automatically control the disk read and write speed, thus it will not choke the RAM.
this is a simple solution to implement. This same concept can be used in some other Technical problem scenarios also
Scenario #2
consider a system where we have implemented a crawler which feeds the data to the Kafka. we need to get the data from Kafka pipeline and store it to Database.
Scenario #3
A User is uploading a huge size of files, we need to store it but, we can’t able to store the size after a certain file size limit. what we can do is, implement the stream which reads the data and compresses it. store it in the server.
That’s it for this article, Hope you like this series. I am planning to write more articles on this series if I can get a good response from this initiative.
If you find this useful, please do share it. Subscribe to my newsletter for further updates. Scenario-based Learning - A New Learning Perspective. Node.js - Part 1
Until then, Happy Coding :-)